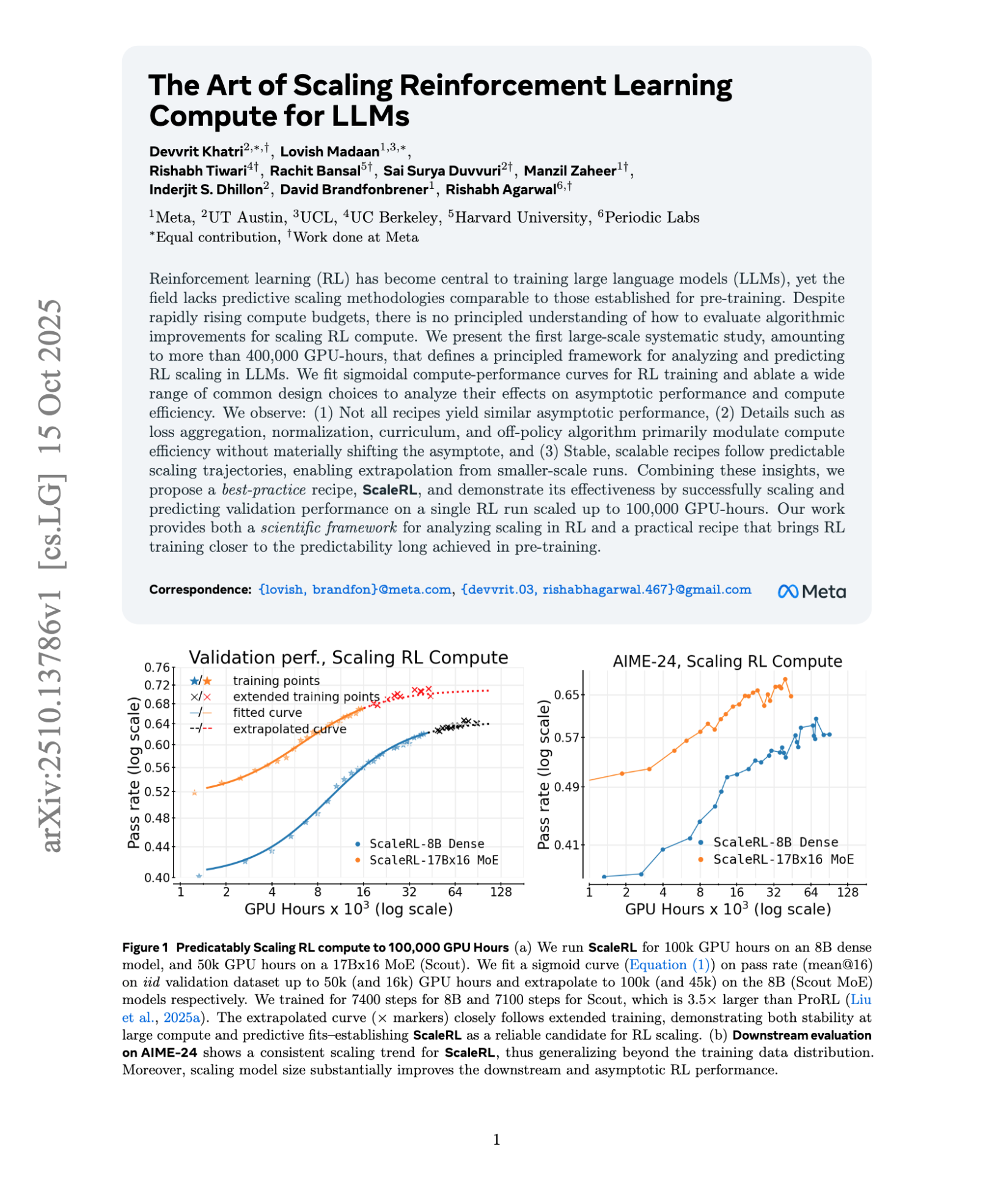
Researchers from Meta with university researchers from UT Austin, UCL, UC Berkeley, Harvard, along with Periodic Labs, posted on arXiv a paper on scaling in reinforcement learning (instead of pre-training).
One of their key findings is that “(3) Stable, scalable recipes follow predictable scaling trajectories, enabling extrapolation from smaller-scale runs.”
ABSTRACT



EXCERPT
Related Stories
I discuss the importance of understanding scaling in analyzing the fair use defense of AI researchers in my forthcoming article in the Houston Law Review: